
[Courtesy of Google]
AlphaGo, an artificial intelligence designed by Google' DeepMind deserved a surprise victory against Lee Sedol, one of the world's best players in an ancient Chinese board game of Go, with its advanced algorithm which was almost equal to or sometimes better than the human brain.
Many artificial intelligences (AIs) have failed in their daunting challenging to Go players in the past, but AlphaGo was different in a historic showdown with Sedol, live streamed by Google from a hotel in Seoul.
In a five-game match, AlphaGo beat Lee Thursday to score two consecutive wins after the Go master, driven to a last-minute countdown, resigned in 211 moves, succumbing to the computer's aggressive and well-calculated attack that made him sweating.
Unlike humans, it stuck to its own unique way, thinking only about each situation it had faced.
AlphaGo’s algorithm uses a combination of machine learning and tree search techniques. It used Monte Carlo tree search, an algorithm which randomly takes samples to come up with a numeric result.
Recurrent neural network (RNN) is the most commonly used method of deep learning. An AI makes decisions based on analyzed, compressed data. An idea of continuity of time is applied in the process. For example, an AI will think every move it takes in a game of Go as an extension from the move it took just before. Also, AI would consider its next planned moves on deciding where to put its stones.
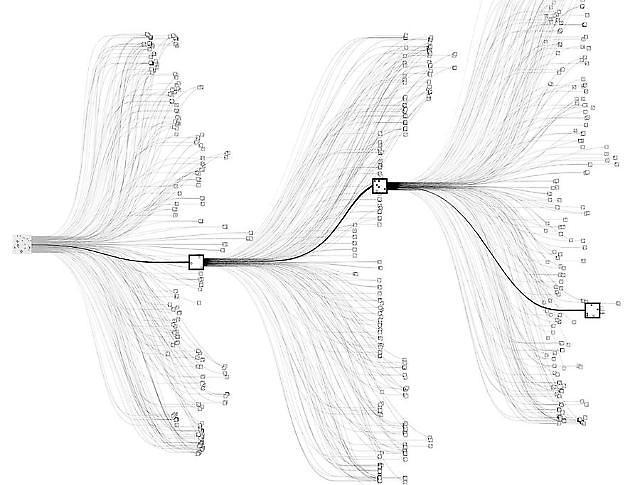
Diagram showing neural network of AlphaGo [Courtesy of Google's DeepMind]
But AlphaGo uses convolution neural network (CNN). This method is what makes AlphaGo special. The DeepMind program does not consider rhythm or placing the order of stones as a human player would.
Continuity is not necessary. AI simulates and evaluates a million times based on records in its database, then selects the best solution. Every positioning of a stone is a new challenge for AlphaGo. It focuses on tackling the situation it faces. Thinking a few moves ahead is not necessary.
AlphaGo's database of its moves in past games is also its great weapon. Google said AI had run up to 30,000 game simulations a day, stacking up its experience and getting better at a game of Go every time.
Such characteristics were clearly shown at the first match with Lee.
When AlphaGo appeared to have made a mistake in placing its stones on the board, it seemed irrelevant. At the time, many experts believed AlphaGo made a bad and critical mistake, but it eventually turned out to be a planned or connecting move, leading to its victory.
Now experts are sure that regardless of the result, AlphaGo will advance further to surpass the human brain in Go because of its deep learning ability. They say it's only a matter of time.
아주경제 박세진 기자 = swatchsjp@ajunews.com
Copyright ⓒ Aju Press All rights reserved.