
SEOUL, December 03 (AJP) - The real battle between Nvidia’s GPU-led ecosystem and Google’s rapidly expanding tensor processing unit (TPU) platform and the outcome hinges on how quickly and at what scale the world's top memory makers based in South Korea can keep up in the rollout of next-gen high-bandwidth memory dubbed HBM4.
Samsung Electronics that had been laggard in the early-stage HBM race is positioned for an unexpected leap as it accelerates the conversions to feed the surging demand for memory tied to next-generation AI accelerators.
The rollout schedules for Nvidia’s Rubin GPU and Google’s Ironwood TPU signal a broader shift inside the AI hardware stack: memory—rather than compute silicon—is increasingly determining speed, scale and deployment timelines across the sector.
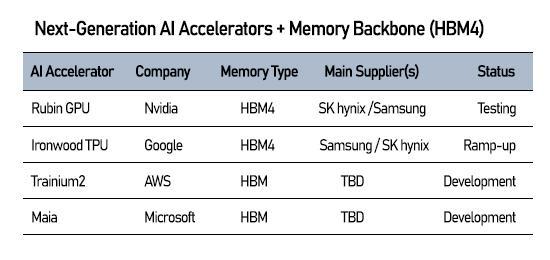
Nvidia’s Rubin platform, slated for mass production in 2026, is built around HBM4 and aims for up to 288 gigabytes of memory per superchip, allowing larger models and faster training cycles.
Google’s Ironwood TPU, still paired with HBM3E, is widely expected to migrate to HBM4 as inference workloads balloon and energy efficiency become a bigger priority.
Other hyperscalers are moving the same direction. Amazon’s Trainium2 and Microsoft’s Maia accelerators are already standardized on HBM-based designs, reinforcing the industry consensus that memory bandwidth—not transistor counts or core architectures—is now the binding constraint.
Most new accelerators integrate six to 12 HBM stacks each, meaning chip rollout is only as fast as memory suppliers can expand output.
That has put Samsung and SK hynix in the middle of the AI arms race.
Samsung recently completed internal production readiness approval for HBM4, signaling it has cleared key development milestones and is prepared to shift quickly into mass production once customer specifications lock in.
SK hynix, the current leader in the HBM segment, finished its HBM4 development earlier this year and has already begun sample shipments to large hyperscaler customers, cementing its early advantage.
But supply, not just technology, may determine the next phase of competition.
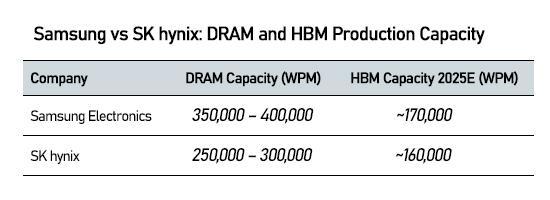
By late 2025, Samsung’s monthly HBM wafer capacity is projected at roughly 170,000 wafers, slightly above SK hynix’s estimated 160,000 wafers, while Micron trails at less than one-third of Samsung’s expected level.
Samsung is pushing that advantage by converting portions of its P3 and P4 facilities in Pyeongtaek into 1c-class DRAM lines geared for HBM production, while racing ahead with structural construction of the P5 plant.
The strategy leans on Samsung’s vast legacy DRAM footprint, which it can retool faster than it can build new fabs.
SK hynix is taking the opposite approach: speeding the ramp-up of new facilities, including boosting utilization at the M16 fab in Icheon and accelerating integration of the Cheongju-based M15X fab. Once M15X is fully operational, SK hynix is expected to narrow Samsung’s capacity edge.
For hyperscalers, these diverging capacity paths are prompting a diversification of processor architectures and memory sourcing.
Nvidia remains the largest consumer of HBM as GPUs dominate AI training workloads, but Google’s growing TPU deployments create a parallel demand stream that strengthens memory makers’ leverage without undermining Nvidia’s consumption.
The result is a split but mutually reinforcing ecosystem: SK hynix remains deeply tied to Nvidia’s GPU roadmap, while Samsung is broadening across both GPU and TPU platforms, supplying memory for Nvidia, Google and Broadcom-linked TPU designs.

Despite the differing strategies behind GPUs, TPUs and custom AI chips, all major platforms converge on the same bottleneck: memory bandwidth and availability.
The industry’s push toward HBM4 underscores how high-performance memory has quietly become the defining resource of AI infrastructure.
For all the attention paid to chip architectures, the Nvidia–Google rivalry may ultimately be determined by which ecosystem secures stable, scalable access to next-generation HBM—and which memory supplier can expand capacity fast enough to keep the AI boom fed.

Copyright ⓒ Aju Press All rights reserved.


