SEOUL, December 15 (AJP) -South Korea's homegrown artificial intelligence language models significantly underperformed compared with leading international counterparts in solving college entrance exam–level math problems, according to a study by a research team led by Professor Kim Jong-rak at Sogang University.
The study tested five major Korean-language AI models against five global models, including ChatGPT, using math and essay questions drawn from university entrance examinations. Results showed a wide performance gap between domestic and international systems.
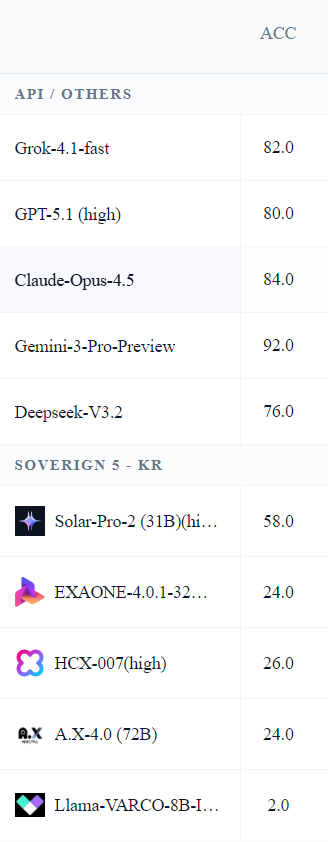
Among the Korean models, only Upstage’s Solar Pro-2 scored above 20 points, achieving 58 points. Other domestic models clustered in the 20-point range, with NCSoft’s lightweight Llama Barco 8B Instruct scoring just 2 points. By contrast, international models recorded scores ranging from 76 to 92 points.
The evaluation consisted of 50 questions per model: 20 high-difficulty math problems covering common mathematics, probability and statistics, calculus, and geometry, as well as 30 essay-style questions sourced from South Korean, Indian and Japanese university entrance exams.
The Korean models tested were Upstage’s Solar Pro-2, LG AI Research’s Exaone 4.0.1, Naver’s HCX-007, SK Telecom’s A.X 4.0 (72B), and NCSoft’s Llama Barco 8B Instruct. International models included GPT-5.1, Gemini 3 Pro Preview, Claude Opus 4.5, Grok 4.1 Fast, and DeepSeek V3.2.
Even when allowed to use Python-based tools to enhance computational accuracy, Korean models continued to struggle. In a separate evaluation using 100 custom-designed questions, international models scored between 82.8 and 90 points, while Korean models ranged from 7.1 to 53.3 points.
When models were given up to three attempts to solve each problem, Grok achieved a perfect score, while other international models reached 90 points.
Among Korean systems, Solar Pro-2 scored 70 points and Exaone reached 60 points. HCX-007, A.X 4.0, and Llama Barco 8B Instruct scored 40, 30 and 20 points, respectively.
“We conducted this test in response to growing questions about how domestic AI models perform on entrance exam–level problems,” Professor Kim said. “The results show clearly that Korean models are still significantly behind global frontrunners, particularly in complex reasoning and mathematics.”
The findings add to concerns within South Korea’s AI industry over gaps in advanced reasoning capabilities, despite strong investment and rapid model development in recent years.
* This article, published by Aju Business Daily, was translated by AI and edited by AJP.
Copyright ⓒ Aju Press All rights reserved.