SEOUL, December 17 (AJP) - Researchers at the Korea Advanced Institute of Science and Technology have developed a new artificial intelligence training method that allows AI systems to learn human preferences more accurately using far less data, even in noisy or uncertain conditions.
KAIST said on December 17 that a research team led by Kim Jun-mo has created a reinforcement learning framework called Teacher Value-based Knowledge Distillation, or TVKD. The approach improves how AI systems align their decisions with human judgment, a long-standing challenge in fields ranging from large language models to recommendation systems.
Conventional preference-based AI training relies heavily on large volumes of comparison data, such as choosing whether option A is better than option B. While effective in controlled settings, the method often breaks down when data is limited or when human judgments are inconsistent, causing unstable learning and unreliable outcomes.
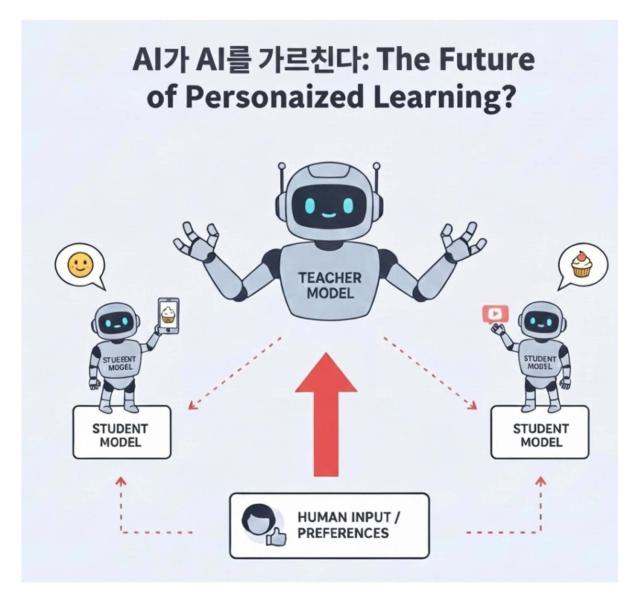
The KAIST team addressed this problem by introducing a “teacher-student” structure. In the new framework, a teacher model first learns how valuable different choices are across full contexts, rather than relying on simple comparisons. The teacher then passes this distilled information to a student model, which learns more efficiently and consistently.
Instead of copying binary judgments like “good” or “bad,” the student model learns why a decision is better by inheriting the teacher’s value-based evaluation. This allows the AI to make more balanced decisions in ambiguous situations and reduces confusion caused by conflicting data.
The researchers also designed the system to account for the reliability of preference data. Clear and consistent data is given more weight during training, while noisy or uncertain inputs are downplayed. This helps the AI remain stable in real-world environments where human feedback is often imperfect.
Tests across multiple AI benchmarks showed that the new method outperformed existing state-of-the-art approaches. The framework delivered stronger and more stable results on widely used evaluation tools such as MT-Bench and AlpacaEval.
Kim said the method reflects how learning works in practice, where perfect data is rarely available. He added that the framework could be applied across a wide range of AI applications that require reliable alignment with human values.
The research was led by Kwon Min-chan, a doctoral student at KAIST, and has been accepted to NeurIPS 2025, one of the world’s leading artificial intelligence conferences. The study will be presented at a poster session on December 3, Pacific time.
The project was supported by funding from the Ministry of Science and ICT through the Institute of Information & Communications Technology Planning & Evaluation.

Copyright ⓒ Aju Press All rights reserved.


