
DAEJEON, March 24 (AJP) - High bandwidth memory (HBM) is what enabled the current artificial intelligence boom, giving chips the speed needed to train large-scale models. But as AI shifts from training to real-world deployment, the industry is running into a different constraint — not speed, but scale.
That shift is beginning to redefine the competitive landscape. The next phase of the AI chip race may hinge not on HBM itself, but on what comes after it: high bandwidth flash (HBF).
Joung-ho Kim, a professor at the Korea Advanced Institute of Science and Technology (KAIST) and dubbed as the “father of HBM,” argues that this shift is not incremental but structural.
In an interview with AJP, he argued the future of AI competitiveness will hinge on how quickly companies adapt their memory architecture to this new reality.
“The memory architecture must be fundamentally restructured,” Kim said. “HBM defined the last decade, but HBF will likely determine the next.”
The urgency stems from the rapid expansion of AI workloads, particularly in inference — the stage where trained models generate responses in real time.
Unlike training, inference relies heavily on key-value (KV) caches, which store intermediate data and grow rapidly as models process longer context windows. What was once a manageable memory demand is now pushing into the terabyte range per system, exposing the limits of existing HBM-based designs.
HBM, built on stacked DRAM, has served as an ultra-fast layer closely attached to GPUs, effectively acting as the system’s “working memory.” But its strengths — speed and bandwidth — are increasingly offset by limitations in scalability and cost. As models expand, simply adding more HBM becomes inefficient and prohibitively expensive.
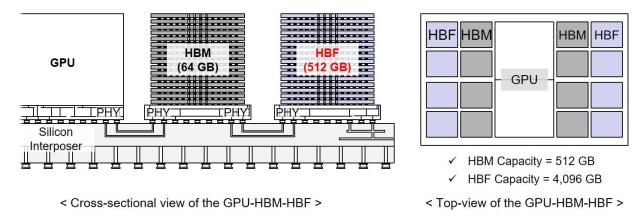
HBF addresses this bottleneck by introducing NAND flash into the memory hierarchy. While slower than DRAM, NAND offers significantly greater capacity at a fraction of the cost, enabling a new layered approach in which high-speed HBM handles immediate computation while HBF stores the massive datasets required for sustained inference.
This shift marks a subtle but critical change in how AI performance is defined. “Once decoding begins, throughput becomes memory-bound,” Kim noted. “At that stage, capacity matters as much as bandwidth.”

The implications are already shaping corporate strategies. SK hynix, which secured an early lead in HBM through aggressive investment in the 2010s, is once again moving ahead of the curve.
In February, the company launched a high bandwidth flash standardization consortium with U.S.-based SanDisk, aiming to establish global specifications under the Open Compute Project. The move signals an attempt not just to develop technology, but to shape the broader ecosystem before the market fully materializes.
The timeline remains long, with engineering samples expected around 2027 and commercialization closer to 2030. Yet the strategic positioning is taking place now, as companies seek to avoid repeating past missteps.
Samsung Electronics, which was slower to commit to HBM in its early stages, is approaching the transition with greater caution. While focusing its immediate resources on next-generation HBM products such as HBM4E and HBM5, it is also investing in NAND-based architectures aligned with the HBF concept. The goal is clear: to ensure it does not lose its footing in another architectural shift.
At its core, the emerging competition is less about a single product than about control over the entire memory system. The question is no longer who can produce faster chips, but who can design the most efficient hierarchy of compute and storage for an AI-driven world.
The parallels with the past are difficult to ignore. SK hynix’s early bet on HBM reshaped the competitive landscape, while hesitation from rivals proved costly. Kim suggests that the same dynamic could play out again.
“If companies fail to invest in HBF now, they could face the same risks we saw before,” he said.
HBF may still be years away from commercial deployment, but the direction of the industry is already becoming clear. If HBM enabled the rise of large-scale AI training, HBF is positioning itself as the foundation for scalable, real-time AI services.
In that sense, the next phase of the AI race may not be decided by raw processing power alone, but by something less visible — the architecture of memory itself.

Copyright ⓒ Aju Press All rights reserved.


